
Среднее значение, медиана и мода — значения, которые часто используются в статистике и математике. Эти значения найти довольно легко, но их легко и перепутать. Мы расскажем, что они из себя представляют и как их найти.
Об этой статье
Для
характеристики рядов
распределения (структуры
вариационных рядов), наряду со средней,
используются т. н. структурные
средние: мода и медиана.
Мода и медиана наиболее часто используются
в экономической практике.
Мода-
варианта, которая наиболее часто
встречается в ряду распределения
(в данной совокупности).
В дискретных вариационных
рядах мода определяется по наибольшей
частоте. Предположим товар А реализуют
в городе 9 фирм по следующим ценам
в рублях:
44;
43; 44; 45; 43; 46; 42; 46;43. Так как чаще всего
встречается цена 43 рубля, то она
и будет модальной.
При
характеристике социальных групп
населения по уровню дохода следует
использовать модальное значение, нежели
среднее. Средняя будет занижать одни
показатели и завышать другие — тем
самым осредняя (уравнивания) доходы
всех слоев населения.
В интервальных вариационных
рядах моду определяют приближенно по
формуле:

Распределение
населения по уровню среднедушевого
месячного дохода
Интервал
1000-3000 в данном распределении будет
модальным, т.к. он имеет наибольшую
частоту (f=35,5). Тогда по вышеуказанной
формуле мода будет равна:


На
графике (гистограмме распределения)
моду определяют следующим образом: по
оси ординат откладывают локальные
частоты, а по оси абсцисс -интервалы
либо центры интервалов. Выбирают самый
высокий столбик, которому соответствует
величина признака с наибольшей частотой
в ряду распределения.
Мода применяется
для решения некоторых практических
задач. Так, например, при изучении
товарооборота рынка берется модальная
цена, для изучения спроса на обувь,
одежду используют модальные размеры
обуви и одежды.
Медиана-
это численное значение признака у той
единицы совокупности, которая находится
в середине ранжированного ряда
(построенного в порядке возрастания,
либо убывания значений изучаемого
признака). Медиану иногда
называют серединной
вариантой,
т.к. она делит совокупность на две равные
части таким образом, чтобы по обе ее
стороны находилось одинаковое число
единиц совокупности. Если всем единицам
ряда присвоить порядковые номера, то
порядковый номер медианы будет
определяться по формуле (n+1):2 для
рядов, где n — нечетное.
Если же ряд с четным числом
единиц, томедианой будет
являться среднее значение между двумя
соседними вариантами, определенными
по формуле: n:2, (n+1):2, (n:2)+1.
В
дискретных вариационных рядах с нечетным
числом единиц совокупности — это
конкретное численное значение в середине
ряда.
Нахождение
медианы в интервальных вариационных
рядах требует предварительного
определения интервала, в котором
находится медиана, т.е. медианного интервала –
этот интервал характеризуется тем, что
его кумулятивная (накопленная) частота
равна полусумме или превышает полусумму
всех частот ряда.

По
данным таблицы определим медианное
значение среднедушевого дохода. Для
этого необходимо определить какой
интервал будет медианным. Используем
формулу номера медианной единицы ряда,
т.е. середины:
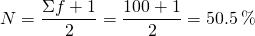
Дробное
значение N (всегда при четном числе
членов) равное 50,5% говорит о том,
что середина ряда находится между 50% и 51%,
т.е. в третьем интервале. Иными словами:
медианным считается интервал, на который
впервые приходится более половины
суммы накопленных частот. Отсюда
медиана:


Для
того, чтобы определить графически
интервал, в котором находится медиана,
по оси ординат откладывают накопленные
частоты, а по оси абсцисс — центры
интервалов. Из точки на оси ординат,
которой соответствует 50.5% суммы
накопленных частот, проводят линию
параллельно оси абсцисс до пересечения
с кумулятой. Из точки пересечения
опускают перпендикуляр на ось абсцисс.
Соотношение
моды, медианы и средней арифметической
указывает на характер распределения
признака в совокупности, позволяет
оценить его асимметрию.
Если M0<Me<Х
— имеет место правосторонняя асимметрия.
Если же Х<Me<M0 —
левосторонняя асимметрия ряда. По
приведенному примеру можно сделать
заключение, что наиболее распространенным
является доход порядка 2715 руб. в
месяц. В то же время, более половины
населения располагает доходом
свыше 3807 руб., при среднем
уровне 4338 руб.

Из
соотношения этих показателей следует
сделать вывод о правосторонней асимметрии
распределения населения по уровню
среднедушевого денежного дохода:

Квартиль –это
четвертая часть совокупности, определяется
как и медиана, только сумму частот
необходимо разделить на 4, а при
определении квартильного интервала,
кумулятивная частота должна быть больше
или равна четверти суммы частот
совокупности.
Дециль –
делит совокупность на десять равных
частей. Определяется аналогично как и
квартиль, только сумму частот необходимо
разделить на 10.
В статистике модой во множестве чисел называется число, которое встречается в этом множестве наиболее часто. Мод может быть несколько: если в наборе данных одинаково часто встречаются два или больше разных числа, его называют соответственно бимодальным или мультимодальным — иными словами, все значения, встречающиеся максимальное число раз, образуют моды данного множества. В данной статье описано, как найти моду (моды) множества.
Что вам понадобится
Средней
величиной называется статистический
показатель, который дает обобщенную
характеристику варьирующего признака
однородных единиц совокупности.
Для
относительной характеристики величины
варьирующего признака и внутреннего
строения рядов распределения пользуются
структурными средними, которые
представлены модой и медианой.
В
дискретном ряду мода — это варианта с
наибольшей частотой.
Пример
расчета моды для дискретного ряда:
Если
ряд интервальный, то Мо рассчитывается
по формуле

Xmo
— нижняя граница модального интервала
fмо-
частота, соответствующая модальному
интервалу
fмо-1
—
частота, предшествующая модальному
интервалу.
fmo+1
—
частота интервала, следующая за модальным
Пример
расчета моды в интервальном ряду
Определяем
модальный интервал 411-150

Для
расчёта медианы в дискретном ряду
необходимо ранжировать (упорядочить),
то есть расположить все значения
показателя в порядке убывания и
возрастания.
Если
ряд с нечётным числом индивидуальной
величины, то медианой является величина
или варианта, находящаяся в центре
ряда.
1,
2, 2, 3,
5, 7, 10
(
Ме = 3)
А
если ряд с чётным числом индивидуальной
величины, то медиана будет средней
арифметической из двух смежных вариант,
лежащих в центре ряда.
1,
2, 2, (3,
5),
7, 10, 11

В
интервальном вариационном ряду порядок
нахождения следующий :
1)
располагаемое индивидуальное значение
признака (интервальна) групп по ранжиру
2)
определяем для данного ранжированного
ряда накопленные частоты
3)по
данным о накопленных частотах находим
медианный интервал
4)поскольку
медиана делит численность ряда пополам,
то следовательно, что величина её
находится там, где сумма накопленных
частот составляет половину или больше
половины всей суммы частот.
5)Далее
медиану рассчитываем по формуле:

— нижняя граница медиального ряда
ime-
величина медианного интервала
Σf
/ 2 –полусумма частот ряда
S
m-1
-сумма накопленных частот, предшествовавшие
медианный интервал
fme-
частота медианного ряда
— сумма накопленных частот, предшествующих
медиальному интервалу
Пример
расчета медианы для интервального ряда

Like the statistical mean and median, the mode is a way of expressing, in a (usually) single number, important information about a random variable or a population. The numerical value of the mode is the same as that of the mean and median in a normal distribution, and it may be very different in highly skewed distributions.
The mode is not necessarily unique to a given discrete distribution, since the probability mass function may take the same maximum value at several points , , etc. The most extreme case occurs in uniform distributions, where all values occur equally frequently.
In symmetric unimodal distributions, such as the normal distribution, the mean (if defined), median and mode all coincide. For samples, if it is known that they are drawn from a symmetric unimodal distribution, the sample mean can be used as an estimate of the population mode.
Mode of a sample
% x is a column vector dataset
% indices where repeated values change
% longest persistence length of repeated values
The algorithm requires as a first step to sort the sample in ascending order. It then computes the discrete derivative of the sorted list, and finds the indices where this derivative is positive. Next it computes the discrete derivative of this set of indices, locating the maximum of this derivative of indices, and finally evaluates the sorted sample at the point where that maximum occurs, which corresponds to the last member of the stretch of repeated values.
Comparison of mean, median and mode
Unlike median, the concept of mode makes sense for any random variable assuming values from a vector space, including the real numbers (a one-dimensional vector space) and the integers (which can be considered embedded in the reals). For example, a distribution of points in the plane will typically have a mean and a mode, but the concept of median does not apply. The median makes sense when there is a linear order on the possible values. Generalizations of the concept of median to higher-dimensional spaces are the geometric median and the centerpoint.
Uniqueness and definedness
An example of a skewed distribution is personal wealth: Few people are very rich, but among those some are extremely rich. However, many are rather poor.
A well-known class of distributions that can be arbitrarily skewed is given by the log-normal distribution. It is obtained by transforming a random variable having a normal distribution into random variable Y = eX. Then the logarithm of random variable is normally distributed, hence the name.
Taking the mean μ of to be 0, the median of will be 1, independent of the standard deviation σ of . This is so because has a symmetric distribution, so its median is also 0. The transformation from to is monotonic, and so we find the median e0 = 1 for .
When has standard deviation σ = 0.25, the distribution of is weakly skewed. Using formulas for the log-normal distribution, we find:
Indeed, the median is about one third on the way from mean to mode.
When has a larger standard deviation, , the distribution of is strongly skewed. Now
Here, Pearson’s rule of thumb fails.
Van Zwet condition
Mode ≤ Median ≤ Mean
F( Median — ) + F( Median + ) ≥ 1
for all where F() is the cumulative distribution function of the distribution.
where is the absolute value.
A similar relation holds between the median and the mode: they lie within 31/2 ≈ 1.732 standard deviations of each other:
Pearson uses the term mode interchangeably with maximum-ordinate. In a footnote he says, «I have found it convenient to use the term mode for the abscissa corresponding to the ordinate of maximum frequency.»
Мода
и медиана –
особого рода средние, которые используются
для изучения структуры вариационного
ряда. Их иногда называют структурными
средними, в отличие от рассмотренных
ранее степенных средних.
Мода
– это величина признака (варианта),
которая чаще всего встречается в данной
совокупности, т.е. имеет наибольшую
частоту.
Мода
имеет большое практическое применение
и в ряде случаев только мода может дать
характеристику общественных явлений.
Медиана
– это варианта, которая находится в
середине упорядоченного вариационного
ряда.
Медиана
показывает количественную границу
значения варьирующего признака, которой
достигла половина единиц совокупности.
Применение медианы наряду со средней
или вместо нее целесообразно при наличии
в вариационном ряду открытых интервалов,
т.к. для вычисления медианы не требуется
условное установление границ отрытых
интервалов, и поэтому отсутствие сведений
о них не влияет на точность вычисления
медианы.
Медиану
применяют также тогда, когда показатели,
которые нужно использовать в качестве
весов, неизвестны. Медиану применяют
вместо средней арифметической при
статистических методах контроля качества
продукции. Сумма абсолютных отклонений
варианты от медианы меньше, чем от любого
другого числа.
Рассмотрим
расчет моды и медианы в дискретном
вариационном ряду:
Определить моду и медиану.
Мода
Мо =
4 года, так как этому значению соответствует
наибольшая частота f
= 5.
Т.е.
наибольшее число рабочих имеют стаж 4
года.
Для
того, чтобы вычислить медиану, найдем
предварительно половину суммы частот.
Если сумма частот является числом
нечетным, то мы сначала прибавляем к
этой сумме единицу, а затем делим пополам:
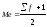
Медианой
будет восьмая по счету варианта.
Для
того, чтобы найти, какая варианта будет
восьмой по номеру, будем накапливать
частоты до тех пор, пока не получим сумму
частот, равную или превышающую половину
суммы всех частот. Соответствующая
варианта и будет медианой.
Ме
= 4 года.
Т.е.
половина рабочих имеет стаж меньше
четырех лет, половина больше.
Если
сумма накопленных частот против одной
варианты равна половине сумме частот,
то медиана определяется как средняя
арифметическая этой варианты и
последующей.
Вычисление
моды и медианы в интервальном вариационном
ряду
Мода
в интервальном вариационном ряду
вычисляется по формуле
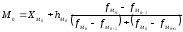
где ХМ0
— начальная
граница модального интервала,
hм0
– величина модального интервала,
fм0,
fм0-1,
fм0+1
– частота
соответственно модального интервала,
предшествующего модальному и последующего.
Модальным
называется такой интервал, которому
соответствует наибольшая частота.
Определить
моду и медиану.
Хм0=6,
fм0=35
hм0=2,
fм0-1=20

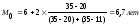
Вывод:
Наибольшее число рабочих имеет стаж
примерно 6,7 лет.
Для
интервального ряда Ме вычисляется по
следующей формуле:

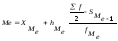
где Хме
–
нижняя граница медиального интервала,
hме
– величина медиального интервала,

–
половина суммы частот,
fме
– частота медианного интервала,
Sме-1
–сумма
накопленных частот интервала,
предшествующего медианному.
Медианный
интервал – такой интервал, которому
соответствует кумулятивная частота,
равная или превышающая половину суммы
частот.
Определим
медиану для нашего примера.
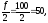
Хме
=6, fме
=35,
hме
=2, Sме-1=47,
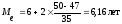
Вывод: Половина рабочих имеет стаж
меньше 6,16 лет, а половина имеет стаж
больше, чем 6,16 лет.
Статистика и математика являются важными частями DataScience. Сегодня поговорим про самые простые и довольно часто встречающиеся понятия.
Медиана — если отсортировать список, например список котиков по мере увеличения их роста, в середине будет находиться котик, обладающий самым типичным размером.
В Pandas есть соответствующий метод median().
Среднее значение — если у нас есть несколько значений, то для нахождения медианы нужно сложить значения и разделить пополам (или же сложить значения и разделить на их количество если их больше, чем два).
Выброс — значение, сильно выбивающееся из ряда значений. Выбросы могут сильно исказить многие статистические методы, поэтому что бы избавиться он них, убирают некий процент самых больших и самых малых значений.
Размах — разница между самым большим и самым малым значением. Так как размах чувствителен к выбросам, для его вычисления применяют межквартильный размах — когда из нашего ряда убраны 25% самых больших и самых малых значений.
Отклонение — разность между средним и самым большим значением.
Стандартное отклонение — для этого нужно сложить все отклонения и поделить на количество значений и возвести в квадрат. std — standard deviation (стандартное отклонение).
P.S. Данная информация является базовой, для ознакомления с основами статистики, если будет интересно, я буду раз продолжить знакомство со статисткой DataScience.
